مقارنة بين Gemini Omni و Qwen Image Edit
Gemini Omni
يُمثل Gemini Omni من Google DeepMind جيلًا جديدًا من نماذج الذكاء الاصطناعي متعددة الوسائط (Multimodal AI) القادرة على إنشاء وتحرير الفيديو والصوت والصور باستخدام النصوص أو أي نوع من المدخلات الأخرى. يعتمد النموذج على مفهوم “Create Anything From Any Input” لتشغيل الوكلاء الذكيين وإنشاء المحتوى التفاعلي داخل منظومة Google AI، مما يجعله من أقوى منصات الذكاء الاصطناعي التوليدي الحديثة في مجالات الفيديو، والـ AI Infrastructure، والـ LLMOps.
زيارة الموقعالمميزات
إنشاء فيديوهات AI متعددة الوسائط.
تعديل الفيديوهات بالمحادثة الطبيعية.
إنتاج محتوى قصير لمنصات السوشيال ميديا.
إنشاء فيديوهات تعليمية وإبداعية تلقائيًا.
تطوير تطبيقات AI Video Editing.
تشغيل الوكلاء الذكيين متعددة الوسائط.
تحويل الصور والصوت إلى فيديوهات تفاعلية.
دعم صناعة المحتوى السينمائي القصير.
تطوير أنظمة AI Storytelling الحديثة.
تشغيل تطبيقات الـ Generative Media والـ LLMOps.
صور من المقال

الكلمات الدلالية

Qwen Image Edit
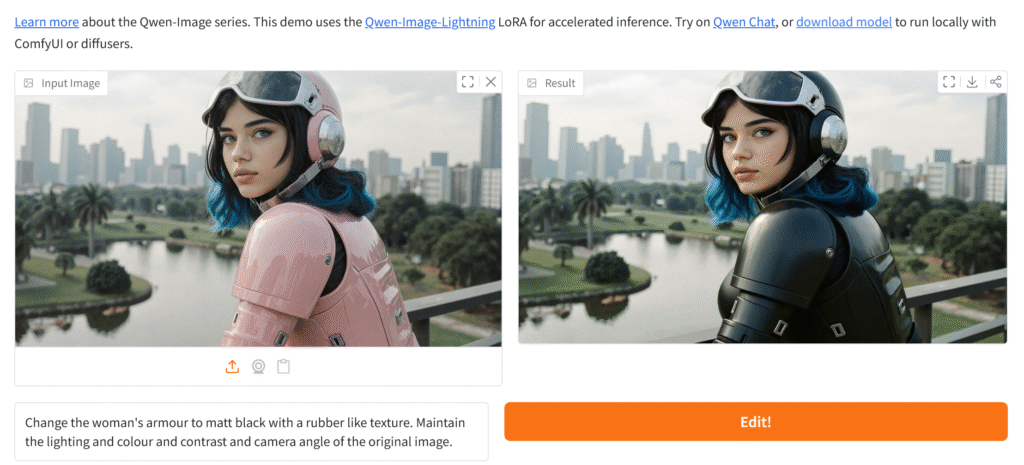
Qwen Image Edit أداة ذكاء اصطناعي متطورة لتحرير الصور بلمسة إبداعية، تُمكّنك من إزالة العناصر، تعديل الألوان، وتصميم صور تسويقية جذابة ومبتكرة بسرعة وسهولة، مما يجعلها الحل المثالي للمصممين، المسوّقين، وصنّاع المحتوى.
زيارة الموقعالمميزات
إزالة الأجسام: مسح الأشخاص أو الأشياء غير المرغوبة.
تغيير الألوان: تعديل لون عناصر معينة مثل الملابس أو السيارات.
تبديل الخلفية: استبدال الخلفية بأكملها.
إضافة عناصر: دمج أشياء جديدة في الصورة بطريقة طبيعية.
تعديل الملامح: تغيير تعابير الوجه أو ملامحه بدقة.
إعادة تكوين الصورة: توليد نسخ مختلفة بأساليب فنية متنوعة.
تعديل الإضاءة: التحكم في الإضاءة والظلال.
تغيير الملابس: استبدال ملابس شخص ما بأخرى.
تحويل الصور: تطبيق أنماط فنية مثل الرسم الزيتي.
إصلاح العيوب: إزالة الخدوش أو البقع من الصور القديمة.
صور من المقال